EasyBuilder Pro Version: v6.09.02 build 2024.10.17
Serial Number or supplier: MSI TEC
I have a particular application in which I am trying to use an action trigger to move a string from PLC memory to the UAC password area. The PLC is an Omron NX over Ethernet/IP I found that I have to format the string in unicode with one character per word and format the ascii strings in unicode as per this article.
This works great but seems to have some adverse side effects.
The problem that I am having is that the UAC password doesn’t seem to like the Unicode. I came to this conclusion when I tried to copy the Unicode formatted string into the UAC password and it wouldn’t login, but if I tried the same with a UTF-8 it works
can you confirm that this is a formatting issue and is there a way to adjust the formatting for better compatibility with these systems? thanks
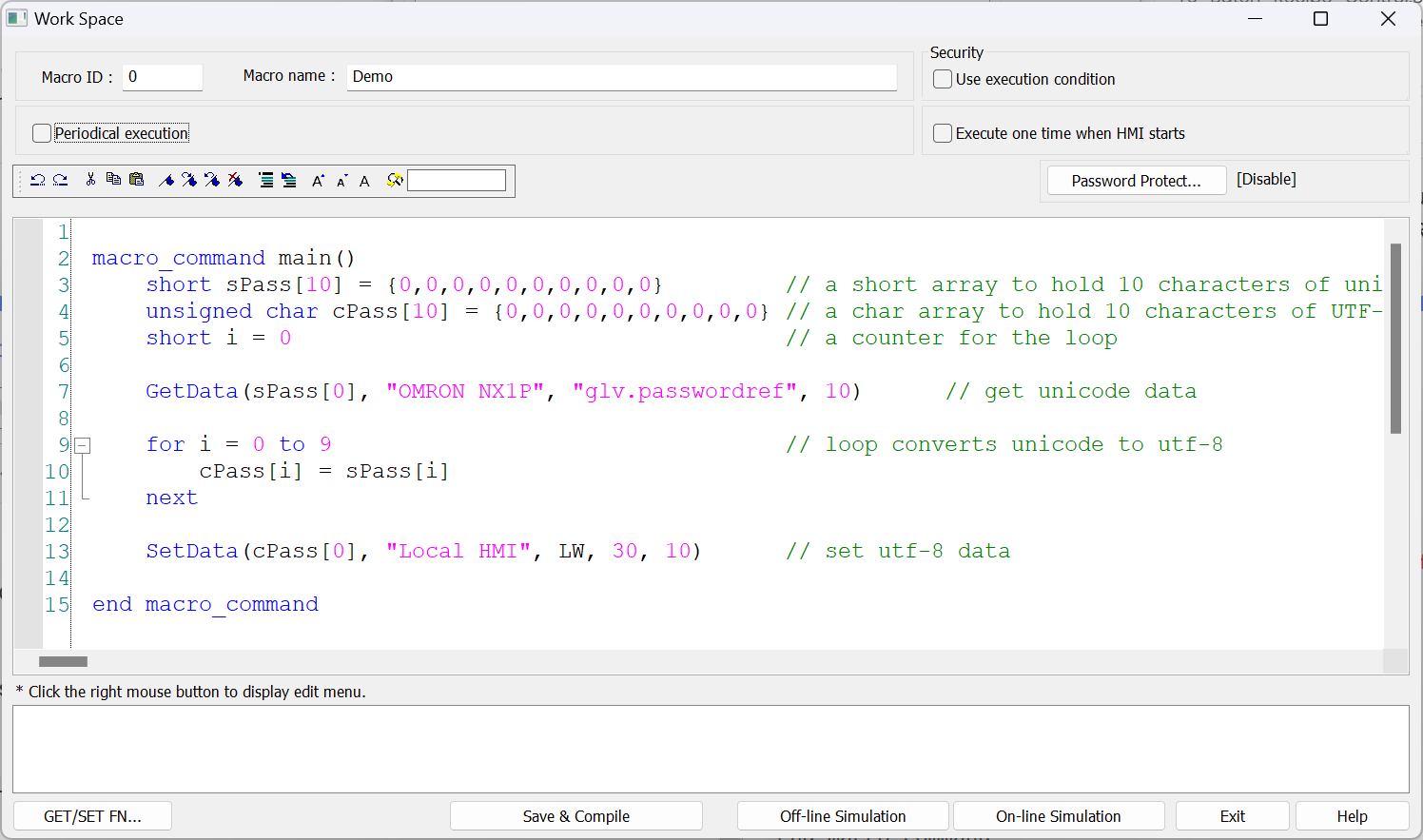
The encoding of strings can be adjusted via macro. A simple way to do this is to read the complete string into a short array and then remap this to a char array as in the following example:
macro_command main()
short sPass[10] = {0,0,0,0,0,0,0,0,0,0} // a short array to hold 10 characters of unicode data
unsigned char cPass[10] = {0,0,0,0,0,0,0,0,0,0} // a char array to hold 10 characters of UTF-8 data
short i = 0 // a counter for the loop
GetData(sPass[0], "OMRON NX1P", "glv.passwordref", 10) // get unicode data
for i = 0 to 9 // loop converts unicode to utf-8
cPass[i] = sPass[i]
next
SetData(cPass[0], "Local HMI", LW, 30, 10) // set utf-8 data
end macro_command
When you have time, can you please implement a similar method and advise if this resolves the issue you? Note: The UAC control address must be remapped to LW memory to use this method.
Brendon. That works great.
I am a little confused as to why though. If you could help me understand.
a short is 16 bits and a char is 8 bits, correct?
how is it possible to set the chars equal to the short elements when the shorts data exceeds that of the char?
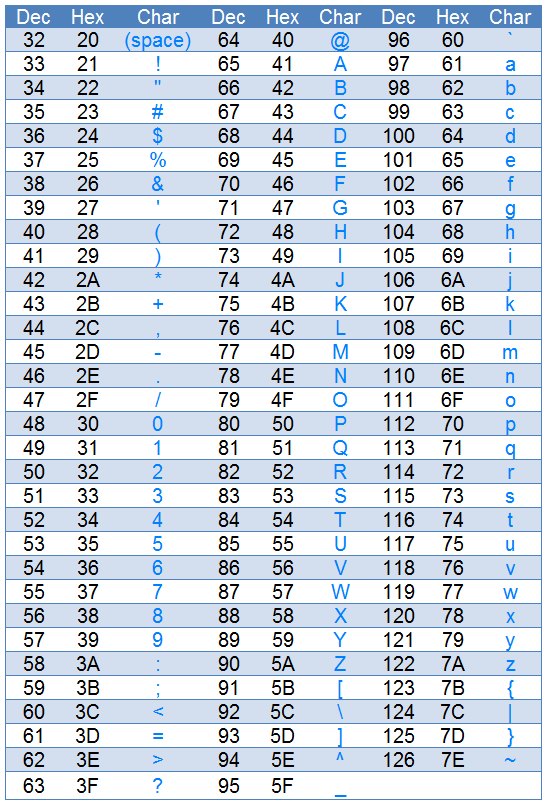
That is an excellent question, the reason that we can convert some character values from Unicode to char is because their values are equivalent. As an example, you may review some decimal values of characters within the Unicode table and compare them to the ASCII table below. In doing so you will find the decimal values of 0 ~ 9 to be the same as well as A~Z and a ~ z.